@Towards Personalized and Semantic Retrieval: An End-to-End Solution for E-commerce Search via Embedding Learning
除了基础的相关性特征(如query token和item title token),本文方案(DPSR)增加了多种个性化特征以提升模型对个性化信息的关注,
用户侧包括:#card
- User Profile:用户画像特征,如用户性别、年龄、消费能力、区域等,用于刻画用户的静态基础特征。
User History Events:用户历史行为特征,如历史点击商品、搜索query、类目品牌偏好、点击率、成交率等。
- User Profile:用户画像特征,如用户性别、年龄、消费能力、区域等,用于刻画用户的静态基础特征。
商品侧个性化特征包括:#card
- 商品品类、品牌、邮寄类型,又如商品、店铺历史表现等。通过增加个性化特征,模型能够捕获用户偏好和商品除文本语义之外的属性特征。
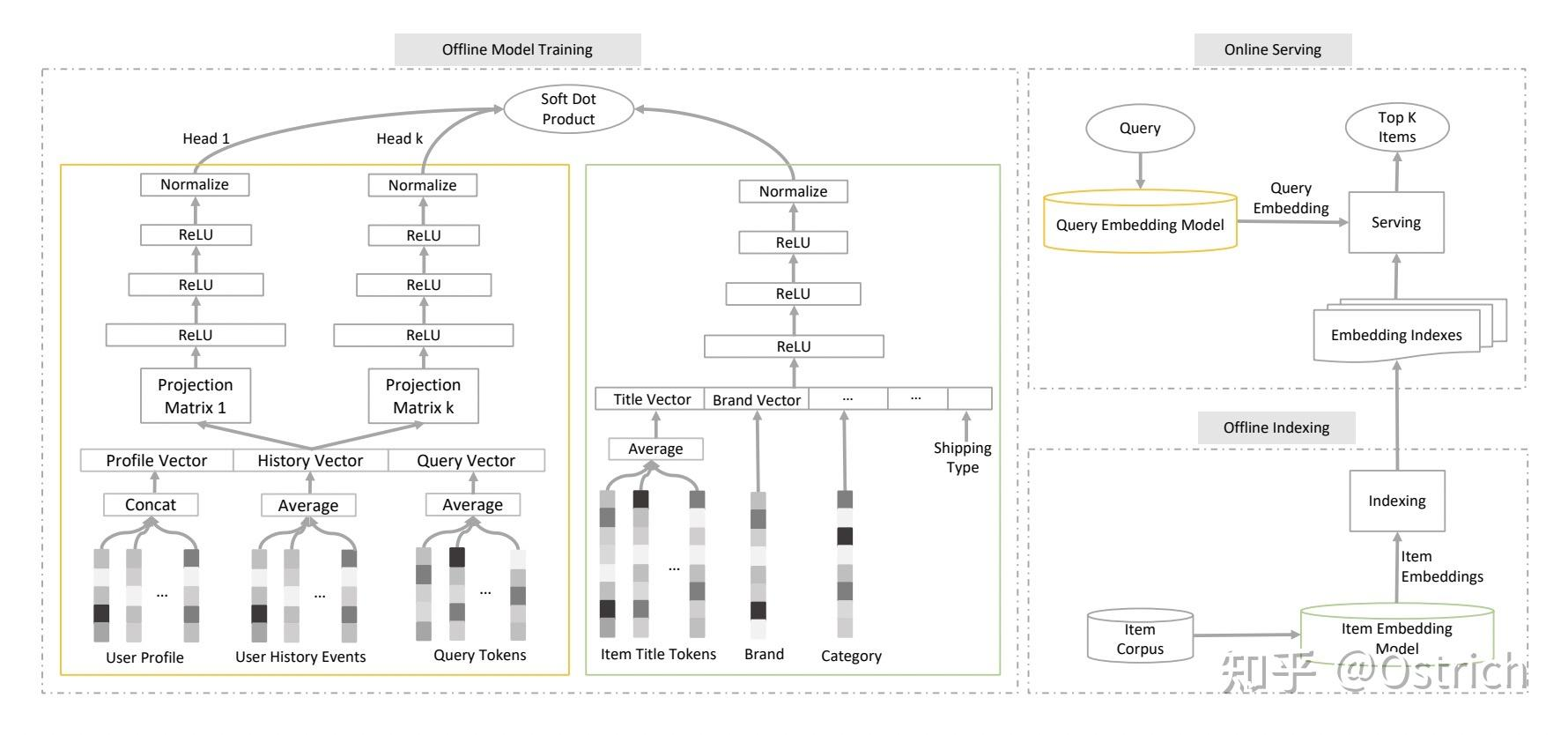
模型采用经典的双塔架构,包括user/query tower和item tower两个模块。各特征离散化后通过embedding average或concat映射到固定维度后拼接,并经过DNN网络分别得到user和item的特征向量。此外,在user/query tower模块使用了multi-head来提取更加多样的特征(有点模型ensemble的感觉)。#card
item tower和user/query multi-head使用attention的方式进行匹配分数融合
Multi-head的attention仅在训练阶段计算,在线检索时,每个head将分别进行召回并通过内积分数截断同样数量的商品进行统一排序。
文章训练数据的构造比较简单直觉:#card
使用用户点击数据为正样本(10亿级别)。
负样本同样没有使用曝光未点击的商品,因为未被点击的商品不一定不相关。
random negatives、in-batch negatives,二者合并作为负样本参与训练 $N_i=N_{\text {rand }} \cup N_{\text {batch }}$
文章指出随着rand负样本比例的增加,商品的个性化(或热度)逐渐变强,更容易点击/成交,相应地相关性也会一定程度下降。
@Towards Personalized and Semantic Retrieval: An End-to-End Solution for E-commerce Search via Embedding Learning